
The Platform
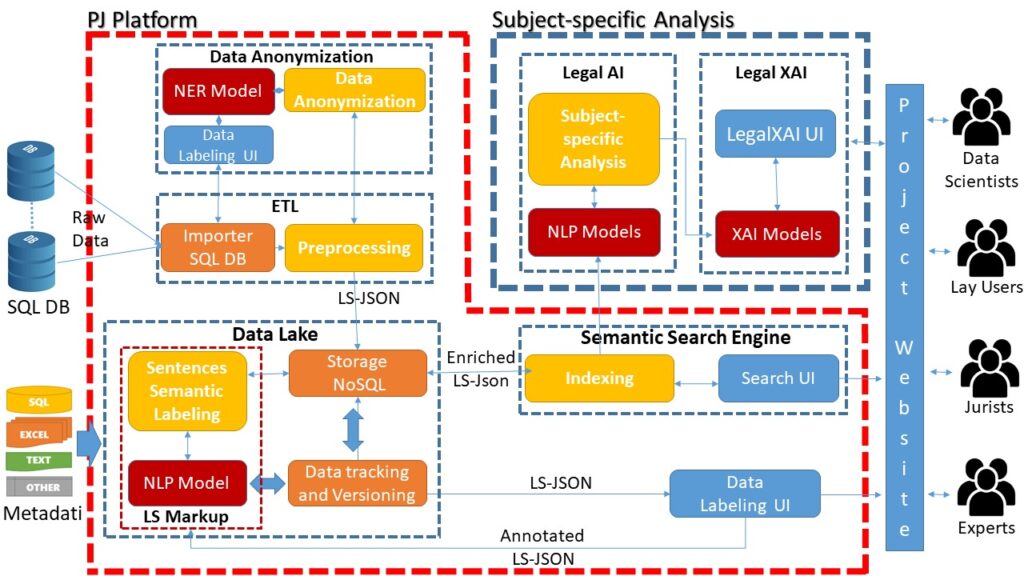
Extract, Transform, Load (ETL)
The ETL node pre-processes legal documents and metadata by converting them into a flexible JSON-based format (LS-JSON) and attaching an anonymized version by interacting with the Data Anonymization module.
Data Anonymization
It uses algorithms based on Named Entity Recognition (NER) Natural Language Processing (NLP) supervised machine learning models for anonymizing the Personal Identifying Information (PII)
Data Lake
PJ centralized repository for handling large amounts of data and reproducing, tracking, documenting, and verifying the integrity and quality of data and experiments
Data Labeling UI
The system integrates a web application for textual annotation in order to obtain high quality datasets for training models, reducing expert labeling errors, applying a consensus model, and verifying adherence to the annotation protocol.
Legal Semantic Markup
(LS Markup)
Automatic annotation of the type of sentences (retrieval, citation, proof, legal rule, reasoning) for extracting reasoning patterns from legal decisions and filtering noise/bias information before training AI models.
Legal Semantic Search Engine
(LS Search Engine)
The search engine indexes LS-JSON data allowing full-text semantic queries on different types of phrases and metadata.
It leverages NLP contextual models for semantically similar information by handling synonyms and polysemes, ensuring qualitatively better results than keyword-based search on inverted lists.
Legal AI
Predictive Justice Platform that will be used to analyze specific legal case studies by deploying predictive algorithms on the different subjects of justice aimed at reconstructing the underlying legal reasoning.
Legal XAI
Legal AI models will be made explainable by the Legal XAI module in order to explain the reasoning behind each decision for different stakeholders, identify possible trends/biases and simplify legal tasks.