
Through the analysis of Judgments contained on our legal database, we wondered about the possibility of isolate different topics
even within a specific Law Section.
We have considered all the Judgments concerning Family Law, which are normally referred to separation and divorce issues,
spousal and child support eventually ordered by Judge on a specific case.
Our main focus was to get as many topics as they reflects the different contents inside the same large amount of documents
to study their potential polarisation.
In data science this goal is accomplished by Topic Modeling techniques which are automated statistical models often used in
Natural Language Processing (NLP) to organise, summarise and extract important informations by a large collection of texts.
The most used method are LDA (Latent Dirichlet Allocation), a generative probabilistic model, which describes each document
as a mixture of topics and each topic as a distribution of words.
Despite his popularity, this models has different weaknesses like the necessity to pre-establish the number of topics to find
and to lead a long series of preprocessing steps to ‘clean’ the texts before the algorithm’s application.
In order to solve this problem, which was particularly consistent in our case study, we decided to apply a new model called
Top2Vec, created by Dimo Angelov and presented on August 2020 on arxiv.org.
How Top2Vec works?
Top2Vec first step is to create a joint embedding of document and word vector using alternatively Doc2Vec, Universal Sentence Encoder
or BERT Sentence Transformer.
These vector representations are placed into the same semantic space to find dense clusters of documents that represent the Topics into the collection.
Similar documents will be placed close to other similar documents and close to the most distinguishing words, while different documents and words will be place far away.
Then, a dimension reduction algorithm called UMAP (Uniform Manifold Approximation and Projection) is applied to solve the “curse of dimensionality” of semantic embedding space that cause a high sparseness of document vectors.
In order to find the clusters, Top2Vec provides the application of an HDBSCAN model (hierarchical density based clustering)
that assign a label to each dense cluster of documents vectors and assign a noise label to all document vectors that are not in a dense cluster. For each dense area the algorithm provides the calculation of the centroid that is called the Topic vector.
The closest word vectors to the Topic Vector became the Topic words.
— Before proceeding to the algorithm application, it was necessary to apply a few steps of anonymization to remove the Judges, lawyers and people names and personal data from the orginal documents.
The Outputs
We carried two experiments on our legal database by applying two different embedding models for creating the joint embedding of document and word vector.
In the first place we run the topic modeling using Doc2Vec, particularly suitable for large datasets and datasets with unique vocabulary.
On second experiment we used a pretrained embedding model (Universal Sentence Encoder Multilingual) which are faster and suggested for smaller datasets.
I° experiment – Doc2Vec embedding model
The algorithm with Doc2Vec embedding model found 61 topics each with a size range between maximum of 588 to minimum of 20 elements. We run a hierachical Topic reduction to extract 3 Topics (we found empirically that was the best number to have Topics with consistent meaning). The size goes from 2490 elements for the first topic, 2082 for the second and 1538 for the third.
Observing the following WordClouds we can say that the three Topic develop around the following hypotheses of meaning:

Topic 0 seems to collect Italian legal words and other typical espressions from procedural vocabolary used to describe the parties and referred to the moment of their constitution in front of a Court.

Second Topic seems to collect words used by Judges to describe the actual case. The first word is “self-sufficient”, then “parties”, “indipendent”, “conditions”, “declaration”, “following” etc.
It’s significant to notice that “self-sufficient” and “indipendent” are two typical words used by Italian Judges to declare the mutual desire of the parties to give up to any form of sustenance.
The third Topic seems to collect all the words used by Judges to define the mutual conditions of the parties regarding the future.
Indeed the most important are: “will”, “he/she will give”, “he/she will pay”, “he/she will contribute”, “must”, “children”, “not more than” etc.
Conclusion
The first experiment lead out a significant output, but comparing our hypothesis to the most significant document extracted by each cluster it wasn’t completely satisfying. We had to consider that this output, despite its significance, was in any case the result of an initial step aimed at reducing the number of automatically identified topics.
This is the reason why we tried with another version of embedding model (Universal Sentence Encoder Multilingual).
II° experiment – Universal Sentence Encoder embedding model
The second experiment with a pretrained embedding model (Universal Sentence Encoder Multilingual) return directly 3 main Topics without the necessity to apply a following hierarchical riduction. Their sizes were: 5141 for the first, 519 for the Second and 450 the third.
Observing the WordCloud we immediatly understand that the output were such more significant and easily interpretable then the first.

This Topic collect all words referred to the main issue of divorce, both considered as legal procedure and as a personal act of free will between the parties. Main words are: “Divorce”, “to divorce”, “Court”, “separation”, “lawyer”, “marriage”, “spouses”, “jurisprudence”.
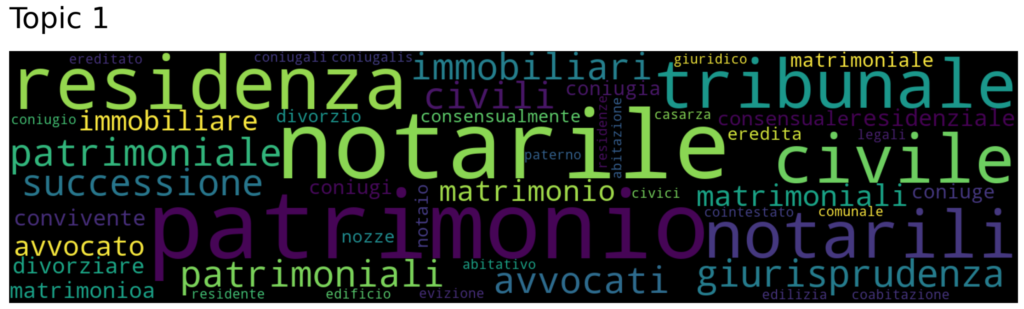
Topic 1 collect all the words concerning patrimonial matters which are related to divorce procedure. We can find “notary”, “patrimonial”, “civil”, “house”, “properties”, “real estate”, “inheritance”, “succession”, “residence”.

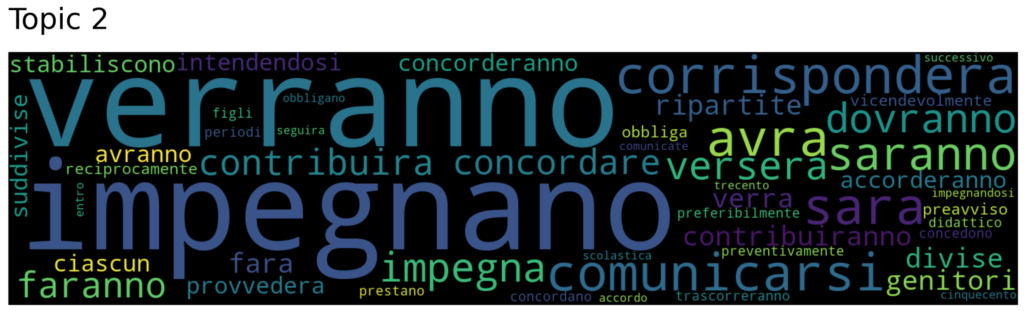
At least Topic 2 summarizes all the concepts around family and child support after the separation or divorce. Main words are: “college”, “school”, “paternal”, “civil”, “fees”, “cost”, “institute”, “university”.
Conclusion
We can affirm without any doubt that the second output was much more significant than the first, considering that Universal Sentence Encoder was the one suggested for smaller datasets and datasets in languages covered by multilingual model.
It has been the better output in order to find significant Topics of matter into the same large amount of documents and in order to explore the main issues discussed into the collection of Family Law.
In this sense, Top2Vec has been providential to accomplish this goal, considered that other Topic Model techniques would be harder to apply.
More esperiments will be lead with the same technique over the entire datasets in order to explore the polarization all over the subjects and the different type of documents.