

In September 2019, Scuola Superiore Sant’Anna and the Trial Court of Genoa signed an agreement to collaborate and settle down an innovative plan of data analysis in order to extract useful informations from raw legal data.
Trial Courts keep a huge amounts of data but, as it usually happens, they are just collected and kept quiet into archives. Data could be an important source of knowledge in order to find analogies and patterns into different legal cases, even different judge’s decisions.
The main sponsor of this collaboration has been Giovanni Comandé, Attorney and full Professor of Private Comparative Law at Scuola Superiore S. Anna, Director of the LIDER-LAB: “For us, at LIDER-Lab, case law has always been a treasure box.” – he said – “We have always explored judicial decisions in conventional and innovative ways. The Permanent Observatory on Personal Injuries is but one example. Over the years, we innovated both on the side of data extraction and in data governance creating groundbreaking datasets and moving towards data science and AI. It was natural to propose over a lunch at a Conference a cooperation to trial courts. And, I must admit, their immediate enthusiastic agreement fuelled a productive collaboration of which we are proud”.
The following analysis are the results of an exploration phase over a portion of Legal Database of Genoa’s Trial Court, Civil and Labour Section particularly. We started, as data scientists team, from a database of judicial documents of more than 330.000 record and 19 attributes that described their metadata informations (such as ID, type of document, original Court, judgement grade, competent Judge, etc.).
We proceed to the pre-processing phase by cleaning the data, dealing with missing values, outliers and duplicates, and finally extracting new metadata of interest.
The pre-processing phase produced a new clean dataset with more than 220,000 records and reduced dimensionality by excluding insignificant attributes. Now, let’s start introducing the dataset (for better understanding we proceed by general questions that could be asked about data).
What kind of document are collected on Legal Database?
As could be seen in data visualization below, there are three kind of document collected in our legal database:
1. D = “Decreto” as “Decree”
2. O = “Ordinanza” as “Ordinance”
3. S = “Sentenza” as “Judgment”
Decrees represent the majority (66,5%), followed by the Ordinances (23%) and the Judgments (10,5%). This compositon could be explained by the fact that Decrees and Ordinances are faster and more effective Judicial acts then Judgments and they could be issued even during the process itself (on the contrary of Judgments, which are definitive final act of a process).
Which are legal act’s grade of justice?
Most of the documents concern the I° grade of justice while less than 1% of legal acts concern the II° grade of justice, or rather comes from Corte d’Appello (Italian Appeal Court).
What period do the legal documents refer to?
Legal documents cover a period from 2008 to 2019, following a progressive escalation in terms of quantity.
In a second time we decided to focus just on the years after 2014 because this is the time when digital process in Italian Legal Courts was entirely introduced and the registration of data become mandatory.
What matters do the legal documents in the database refer to?
In the database, the only attribute that described the document subject was a numerical code “CodiceOggetto” (“SubjectCode”). So, we decided to create a new classification of categories that could be more easy to understand and explore. We used the typical hierarchy of classification for legal documents adopted by Italian Courts for telematic process, considering the possible new codes that could be introduce year by year.
- Most of the documents concern about “Procedimenti speciali“, id est “Special proceedings” of various kind (29%);
- Then we have legal acts concerning about “Diritti della persona” (“Individual rights”) 21,5% ; “Obbligazioni e contratti” (“Obbligations and contracts”) 14%; and “Famiglia” (“Family”) 10,5% ;
- We discovered a consistent category of missing values (“altri” or “others”) 7%;
- Other institutes and special laws (“Istituti e leggi speciali“) (4%);
- We distinguished categories concerning specifically for Labour Section: “Procedimenti in materia di lavoro” (“Labour proceedings”), “Rapporto di lavoro subordinato” (“Employed”) and “Previdenza” (“Welfare”) both 2%; “Pubblico impiego” (“Public emplyment”), “Processuale” (concerning about “Labour trial”), “Assistenza” (“Assistance”), “Parasubordinazione” (“Para-subordinate employment”);
- Then we have categories for different Civil Section Matters like “Diritti reali” (“Property”), “Processuale” (“Procedural Law”), “Pubblica Amministrazione” (“Public Administration”), “Successioni e donazioni” (“Inheritance Law and Donations”), “Persone e società” (“Corporate Law”), “Industriale” (“Industrial Law”) and “Diritto Agrario” (“Agrarian Law”)
(In the following data visualization you’re able to choose the reference period by using data slices above and type of documents)
The following data visualization is shown to clarify the percentage of each type of documents (Decree, Ordinances and Judgments) for each subject previously discovered.
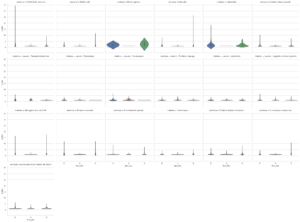
How are the fascicles distributed on the various subjects in terms of consistency?
In our legal database there’s a variable that reports Fascicle-ID: each of them contains a single legal document or multiple.
We needed to study the consistency of each fascicle by distinguishing each subjects and type of documents.
It turns out the best way to visualize the result was a series of violin plots which are basically a combination between box-plot with kernel density plot.
You can study the fascicles’s consistency divided by each type of documents on x-axis: decrees, ordinances, and sentences/judgements while on y-axis are indicated the number of documents contained on each fascicles.
A bigger widht of the violin’s body indicates a greater concentration of the observations in that given value while the long-tail indicates a fewer observations (most of them are 1:1 scale) on the higher values.
Pingback: Exploring Trial Courts Legal Databases: Part 2 – Length of legal documents – PredictiveJurisprudence